Osama Bin Laden and Other Bloggers Conjured up by Google AI
 Osama bin Laden — a popular blogger?
Osama bin Laden — a popular blogger?My friend — who?!#
Nothing that complies with the laws of nature -- known or unknown -- is impossible. So I cannot say that the probability of Tony Judge turning into Osama bin Laden is exactly zero. Particularly if Google indicates that's the case!
But it is highly improbable. Believe me. Tony may be interested, as many of us are, in the enigmatic and elusive billionaire that enjoys such a high visibility on FBI's list of most wanted terrorists, but Tony is not Osama. I know him. Tony is one of my best friends. It's not his style, anyway. Honest to Hawking. Okay?!
Really, it's even less probable than a theory that this is Osama bin Laden's devious stunt aiming to deprive Tony, and hordes of other unsuspecting bloggers across the Internet, of their authorship attribution!
Phantom impersonator#
So then, why is it that some of Tony's articles, which he publishes on his website laetusinpraesens.org, are signed "by O bin Laden"?
Search results tend to shift with time but, still at the time of reviewing this article, querying Google for
site:laetusinpraesens.org osama
brings up a few links, apparently authored "by O bin Laden", right on the first page.
Here's a screenshot saved on Saturday, January 29, 2011:
 Google search results for keyword "osama" for site laetusinpraesens.org
Google search results for keyword "osama" for site laetusinpraesens.orgSee the 2nd result from the top. Note the author's name, in grey colour, underneath the link.

HTML standards ignored#
This situation would be funny if it weren't so sad. The HTML language provides a perfectly good <meta> tag to define the author of any web page. However, Google has either decided to ignore it, or uses it in a non-transparent manner. Not nice, but hey: in the real world, a mammoth enterprise like that can afford to make their own rules.
The problem is that Google does not provide any coherent alternative guidelines for defining authorship. Mentioning the page's author in other meta tags, as suggested by some (e.g. here), may help -- but it may confuse Google's algorithms even more. For what if there are more authors? What if the person's name is such that it modifies the meaning of a sentence? Will the bot understand and extract the right bits from the various longer texts? I seriously doubt it.
For authors, not knowing the rules or logic of Google's algorithms, the results seem arbitrary and unpredictable. It may even be that their tamper-proof logic of how to extract authorship information is so secret that even Google cannot google it back. The results we see appear to support the possibility that the search engine is failing spectacularly at properly recognizing authors of web pages it indexes.
Mentally challenged AI#
It seems rather clear that the AI bot responsible for sorting out the semantics has pretty much lost it. Search results show author names that seem to be a product of a feverish artificial mind. Instead of infantile dreaming of electric sheep, the Google robot appears to amuse itself by playing cruel jokes on web authors.
For example, the source code of the above article correctly indicates that it has been authored by "Anthony Judge": <META NAME="Author" CONTENT="Anthony Judge">. Yet Google somehow detects the authorship as "by O bin Laden":
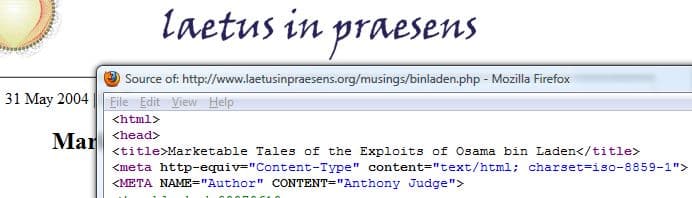
Prolific CF Reactor#
O bin Laden is not the only apparent plagiarizer of Tony's articles. By far the more successful is a certain CF Reactor.
Here's an example:

Again, the page's source code documents that the correct meta tag has been used:
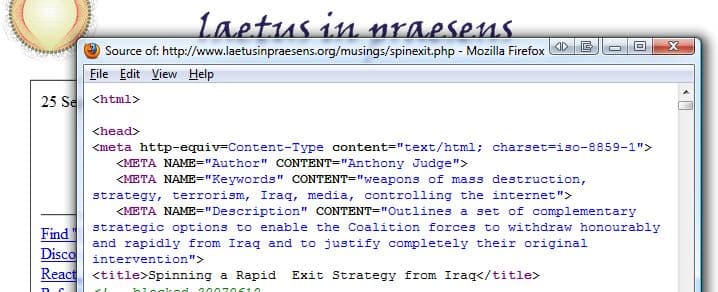
Encountering that particular name all over Google, Tony grew curious, and he was trying to find out who was "the guy" that was apparently taking the credit for his articles. He could not find anybody of that name, so he decided that it had to be some sort of disruptive information aggregator ("reactor") somewhere on the web. But he could not find any.
Then one day he asked me for an opinion and together we had a closer look at this example, and its source code. Luck had it that we noticed that somewhere deep in the menu of the page there was a link to another article of Tony's, entitled "Cognitive Fusion Reactor".
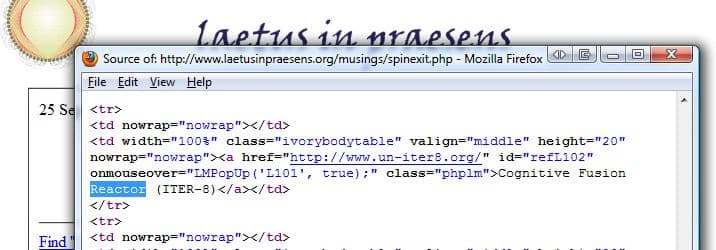
So, apparently, the bot somehow came to the conclusion that this was the author of the page and formatted the name to the neat format: "CF Reactor"!
That clue led us to the discovery that the "Author" meta tag in the original page, on another domain (un-iter8.org), was set to "ITER-8: Cognitive Fusion Reactor", like this: <META NAME="Author" CONTENT="ITER-8: Cognitive Fusion Reactor">.
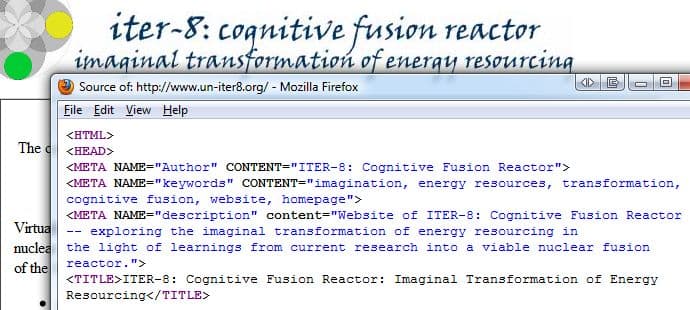
All right, so that particular little mystery cleared up. It simply was a mistake of Tony's. People, like bots, are not infallible!
Robot on a rampage#
But the above does not provide an explanation for how "O bin Laden" became the author of e.g. the first article above because, as we have seen there, its "Author" meta tag is correct.
Also, it is strange that Google, which normally does not pay attention to the "Author" tag (indeed, it appears to skip it) did pick up on it in the case of un-iter8.org.
And the really maddening thing is that instead of keeping this finding isolated to the one page, the Google bot went ballistic and tagged at least five hundred other articles as authored "by CF Reactor". All of them on Tony's domain laetusinpraesens.org (even though the tag was from un-iter8.org). And completely ignoring the fact that all those articles have had their "Author" meta tags correctly set to "Anthony Judge".
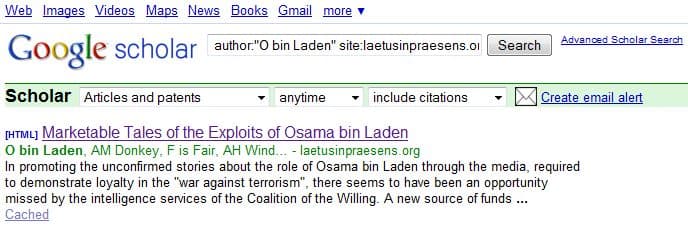
Infested Google Scholar#
Google Scholar, the search engine specialized in "indexing scholarly literature", also appears to believe Osama bin Laden is the true author of some Tony's articles:
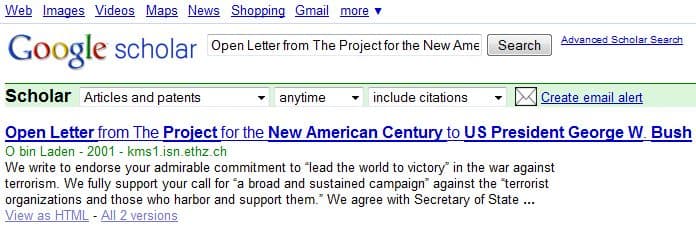
Rather amusingly, in Google Scholar there is even a PDF document, called Open Letter from The Project for the New American Century to US President George W. Bush, that is labelled by Google as authored by O bin Laden:
More plagiarizers#
Apart from O bin Laden and CF Reactor, there are many other curious "authors" of Tony's articles, although less frequent, including WN Renaissance, G Ass, T Steps, A Disagreement, A Type, ghosts of real people such as A Einstein and WB Rayward, F Reactor (surely family of CF?), M Lanthanides -- maybe a chemist, a geeky someone called IP Value, scary-sounding UR Altersschwäche and IG a Terrorist, culminating in somebody inconceivably called A an institutional Apocalypse!








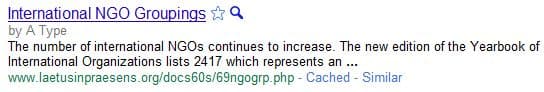




Other research#
The phenomenon of "phantom authors" has been experienced by others, especially with respect to Google Scholar. The earliest mention I find is a pithy article published on Monday, August 31, 2009 in the Chronicle of Higher Education article Google's Book Search: A Disaster for Scholars by Prof. Geoffrey Nunberg, a linguist at the University of California at Berkeley. The same author, in article Google Scholar: another metadata muddle, published on the academic blog Linguistic Data Consortium hosted by the University of Pennsylvania on Saturday, September 26, 2009, laments "numerous missing author names, and phantom authors assigned by the parser that Google elected to use to extract metadata, rather than using the metadata offered them by scholarly publishers and indexing/abstracting services".
Prof. Peter Jacso from the University of Hawaii at Manoa, in a journal article Newswire Analysis: Google Scholar's Ghost Authors, Lost Authors, and Other Problems, Thursday, September 24, 2009, bitterly complains that "Google's algorithms create phantom authors for millions of papers. They derive false names from options listed on the search menu, such as P Login (for Please Login). Very often, the real authors are relegated to ghost authors deprived of their authorship along with publication and citation counts."
So Tony is not the only victim. Given the current size of the Internet, there may be millions of people affected by this problem!
Google's embarrassment#
Not only it appears that the AI responsible for this faux pas is pretty dumb -- the situation also represents an embarrassment for Google, and it is quite possibly even insulting to some of the affected authors. How does one earn to have his/her article appear to be signed by others, by ludicrous invented names, or indeed by the allegedly worst terrorist in the world? And conversely, isn't it unfair even to the said terrorist, who at the moment cannot raise objections without risking of being killed by a drone later that day, to be attributed authorship of random web articles he has probably never even seen?
At first sight it may seem funny to see such a half-baked algorithm coming from a mighty Internet giant such as Google. But the amusement quickly dissipates if there are hundreds or thousands such cases, damaging the good names of the authors, depriving them of their visibility, citations, or income. But there is no sign that Google would be scrambling its engineers to fix the issue.
Bug exploitation#
Of course, what we deal here is definitely a bug for which Google is responsible. Their metadata parsers do not operate in a transparent manner, and bad quality results are allowed to plague search results. But there surely is a rational solution precisely how Google's semantic althorithms misinterpret the information found in pages they crawl, and how do the findings impact other pages. I fail to comprehend why does it take Google such a long time to either fix the problem, or at least hide it from public eye.
One potentially serious consequence of Google's neglect of this issue is the possibility that some clever nerd will experiment with the code long enough to find an efficient method how to make use of the bug for their own purposes. Then they could easily craft any web page so that it would appear to be written by whoever else, a celebrity or some famous politician, thereby increasing their websites' visibility and boost their income from advertising. Given the time that has elapsed since this behaviour was first spotted, it is very probable that this already happens. Who knows -- perhaps majority of author names, displayed by various Google search services, already are fake. If that were the case, ultimately it would amount to a misappropriation of the income and trust that Google gets from its advertisers. As they clarify at their Corporate Information page : "Google generates the majority of [its] revenue by offering [...] highly relevant advertising".
Just google it#
Let's admit it: we use Google to search for pretty much everything these days. Latest gossip and news, from one-night-stand stories through pictures of a shocking local burglary to what really happened (or did not) on 9/11, we look up the correct spelling of "weird", the most authentic grandmother's recipe for apple pie, what's on in the automatically detected cinemas near where we are, or the Monster group, or the name of the cathedral we have just photographed with a smartphone, and we share it with our Dunbar's number of friends. We google it all. We ditch whatever "old", more material sources we used to use before. The original meaning of "browsing" is now statistically less frequent than the web one. If we are forced to leaf through a printed phone directory we feel the urge to type a word instead of going through the indices. We love Google because it provides instant answers. And we grow dependent on it.
This is all well. This is the age of a world-wide digital network, with virtual AI creatures tirelessly working out tasks on our behalf, chattering at the speed of light. This is the exciting future many of our ancestors tried to imagine but none of them really managed.
This is all very fine -- except for when the robots get it wrong and there is little we can do about it. A glitch in the algorithm becomes global, a set of circumstances that were assumed never to happen replicates in microseconds, an omniscient artificial mind that suddenly does something very stupid.
Below the radar#
In an attempt to point out the problem and get help from Google, Tony started this thread in Google's "webmaster central" forum on Tuesday, December 7, 2010. An enthusiastic somebody called "Autocrat: Top Contributor Webmaster Help Bionic Poster" (whatever that means!) attempted to assist. But no official representative of Google has reacted.
Weeks later, not having received any meaningful solution, Tony posted an account of this case in Aliases of Anthony Judge Identified by Google Search. In it, quite touchingly, he strives to clarify that "the author of the documents on [Laetus In Praesens] site is Anthony Judge, unless otherwise specifically indicated in the text of the document itself. Authorship can be confirmed by viewing the source code of any page where this is so stated in the relevant HTML meta tag for 'author'". It seems rather pathetic that individual bloggers like him have to laboriously explain their identity against the sweeping assertions of an omnipresent entity like Google!
For comparison, on Friday, November 26, 2010, the New York Times ran a story, A Bully Finds a Pulpit on the Web, about somebody who ended up buying a wrong product on the Internet just because a seller of imitations successfully fooled the page ranking mechanism of Google Search and got to the top of the search results. On top of that, the seller threatened and harassed the customer when she demanded her money back. Now, that did get the attention of Google, they called in the relevant team and solved the issue, and on Wednesday, December 1, 2010 Amit Singhal (Google Fellow), posted an article about the "loophole" (although belittling it as just "an edge case and not a widespread problem in [Google] search results") on the Official Google Blog entitled (rather unimaginatively) Being bad to your customers is bad for business.
I believe that, if this affected somebody who has enough time and money to employ a lawyer skilled in class action and Internet matter, especially in a litigious society like there is in the USA, Google would possibly run the risk of ending up paying a fortune in damages for a defamation of countless authors.
But with regards to Tony's case, it seems, there is little we can do to get Google to wake up and take this problem more seriously. I suspect nothing will happen unless, one day, a writer with a much more famous name and influence, say Michael Moore, John Simpson, or Greg Palast, let alone someone like Oprah Winfrey or Lady Gaga, finds a work of theirs signed "by O bin Laden" on Google. I am already looking forward to the furore they will set in motion :-)
Update#
At the time of reviewing this article (Saturday, February 12, 2011), the situation is still the same -- there is no reaction from Google nor any other sign of improvement of this situation. It appears to be near impossible for a common person to get a reply from any human working for the Mountain View behemoth. Any message is immediately dwarfed by the total volume of communication the giant handles -- or ignores. Regrettably, Google seems to have become too big and the responsible people hold their noses too high to bother about mere earthlings. Denigration of some Anthony Judge, and other authors, seems to be far below the radar of the Internet giant. Perhaps they are too busy with "organizing the world's information". Only, some results of their work gradually become so confusing that I wouldn't wonder if they failed to notice even if the real Osama happened to plagiarize Tony's articles.
")
- https://en.wikipedia.org/wiki/Anthony_Judge
- https://en.wikipedia.org/wiki/Osama_bin_Laden
- https://www.laetusinpraesens.org/bio/tj_alias.php
- Conflict in description meta-tag between author content and displayed snipp
- Google Scholar's Ghost Authors | Library Journal
ENGLISH ARTICLEDECEMBER 07, 2010 ~ AUGUST 27, 2011